Shadershop Notes
December 2014
On the main Shadershop page I discuss “why” you might want a direct manipulation interface for programming shaders. Here are my notes on “how”.
I take a tour through previous incarnations of Shadershop, with a focus on motivations and features that got left on the cutting room floor. Then I gesture at some possible futures for direct manipulation shader programming. Finally I document my development process—my own approach to making these interfaces.
The target audience for these notes is other creators who are pushing towards new ways that we can richly collaborate with computers. This document is long—favoring coverage over cohesion—but I hope there are some nuggets that you’ll find useful in your explorations.
Contents
- Evolution
- Origins
- First Prototype
- Second Prototype
- Shadershop
- Future Directions
- Showing Composition
- Additional Visual Representations
- Development
- Design of the Semantics
- Design of the Interface
- Implementation of the Semantics
- Implementation of the Interface
- Graphic Design
- Bootstrapping
Evolution
Shadershop is just the latest incarnation in a series of prototypes. Here I tour through its predecessors and discuss noteworthy features.
Origins
The idea of directly manipulating shaders began with two prototypes I made for the Pixel Shaders project.
The first was an interactive visualization that let you explore a mathematical expression by breaking it down into pieces. In shaders you often come across magical one-liners that perform some signal transformation, for example abs(mod(x, 2.) - 1.) which makes a signal “bounce” between 0 and 1.
Like a long sentence with unfamiliar words, these can be tricky to parse for beginners. But experienced programmers know to build understanding in parts: figure out what each subexpression does and then figure out how they combine to make the whole expression. You keep breaking the problem down into subproblems until your subproblems are small enough that you can wrap your mind around them. Then build back up again.
I tried to capture this experience through this cartesian graph visualization. The expression is broken down into subexpressions exactly as the computer would parse it, as in an abstract syntax tree. You can then hover any subexpression to see its graph, and as you move towards the root of the tree, you can see how each modification to the expression transforms the graph.
The goal is to get the programmer thinking in terms of transformations, using functions to sculpt signals. I thought it might be neat to augment a visualization like this with a manipulation interface so that you could sculpt the signal by applying functions to it, like applying filters to an image in Photoshop.
I had the opportunity to try this during my Eyebeam/Mozilla fellowship for Pixel Shaders. Eyebeam is embedded in the “Arts” world and as such the venue for expression is the gallery or exhibition. Typically to learn programming requires sitting and concentrating alone for hours. How do you convey the experience of shader programming to gallery visitors who might poke at your installation for thirty seconds and want to hang out with their friends while doing it?
Refractor was my attempt to satisfy this design constraint.
Visitors start with a base image (or live webcam feed) and apply layers of filters on top. Each filter is just a built-in GLSL primitive (abs, sin, etc.). Each layer can be given an individual affine transformation. I knew from Recursive Drawing that specifying affine transformations through direct manipulation (and especially multitouch) is very natural.
There’s no code to type and every action you take has immediate visual feedback. Though something I noticed is that visitors would sometimes hit Reflect, and then hit Reflect again, which won’t do anything. Then they get a very confused look on their face because their action had no immediate visual feedback!
To make it more of a social experience, I set up the installation so that the interface is mirrored on a large screen. Interaction takes on a performative quality. Visitors are always delighted to discover the live webcam feed and selfies ensue. The live webcam feed also shows that you’re not manipulating an image, you’re manipulating a spatial transformation—the base image is arbitrary.


Refractor was fun to play with, but I was disappointed that it could not be used to create arbitrary spatial transformations. I wanted a direct manipulation interface for shaders that was as mathematically expressive as typing GLSL code directly.
Concatenative Prototype
My first attempt took the “series of transformations” idea of Refractor and applied it to the simpler domain of one-dimensional functions, represented visually as a cartesian graph.
http://www.cdglabs.org/ShadershopConcatenativePrototype/
Spreads
Some transformations take additional parameters, for example + and *. When you hover over a parameter, you see a “spread” showing how the resulting graph would change if you were to scrub that parameter.
When you have a parameter of a function or of a program, you fundamentally need to understand how changing that parameter changes the result of the function. One way to do this is with good labels: give your variables good names. An additional technique is to make parameters scrubbable, so that you can conveniently see how changing the parameter changes the result with continuous feedback.
The spread technique is yet another way to see how a parameter affects the result. It is even quicker than scrubbing, though you can only use it when the spread can be effectively shown without being visually overwhelming.
Transclusion
Parameters can be transcluded across multiple transformations. I think transclusion of values is more natural than referencing variables by name in direct manipulation interfaces.
An advantage of transclusion is that you never have reference errors. What was a name is now just a label. Like a comment. You can write anything here, and the label changes anywhere the shared value is used. Two different values can have the same label (though that’s ill-advised) and there won’t be a “collision”. A value can have no label (an “anonymous” value) but still be reused. The programmer can defer the question of “what should I call this” until she’s ready to address it.
I extend the “drag to transclude” gesture in order to reuse computed values anywhere that constant values can be used. That is, parameters for functions can be computed values, not just constants. To do this, you just drag the graph thumbnail.
Literate Prototype
The first prototype provided a single linear series of transformations—data flow through a single, non-branching pipeline. Crude branching pipelines were hackable by “resetting” and transcluding previous graphs as in the above video.
My second prototype aimed to provide more natural support for branching data flow and also to implement parameterized function (“lambda”) abstraction.
Additionally, there was activity around the lab about explorable explanations, so I was interested in seeing if a direct manipulation programming interface could be used for interactive literate programs—“source code” that explains itself to its reader and provides opportunities to experiment on it within the context of reading.
http://www.cdglabs.org/ShadershopLiteratePrototype/#noise
Parameter Abstraction
You make a function by first creating a concrete example, then specifying that a value should be parameterized by dragging it up into the function definition area.
Start concrete, then generalize. This is the “create by abstracting” principle from Bret Victor’s Learnable Programming essay.
By first creating a concrete example, all functions automatically get default arguments. Thus in the “autocomplete”, you can immediately see the effect of a function (with its default arguments). This is “create by reacting” from Learnable Programming.
Shadershop
I think the above prototype worked well for experimenting with existing programs. But creating new programs within the interface still felt like coding to me. It took on the same rhythms—that same kind of stutter between having an idea and implementing it.
Yoshiki Ohshima showed me an eToys example about adding sine waves to produce a sawtooth wave and asked if we could try to produce it using the above prototype. I think we eventually got it but the interface didn’t help.
I thought about how one would ideally build the sine waves example and came up with this:
This is the moment everything came together. For me, the seed that grows these projects is an interactive prototype that demonstrates the feeling of a simple example. Once I capture the core feeling, everything else follows.
Often at the beginning of a project, what all the pieces are and how they’ll all fit together is cloudy. A good approach is to pick a specific example and then make just those pieces you need for the example and fit them together. Don’t generalize, just get the basic example working! This can give a project its initial momentum.
Radical Representation
We tend to conflate the activity of programming—specifying the behavior of a system—with the representation of textual code. We think programming is coding. This is the same trap as conflating mathematical reasoning with the symbols drawn on school chalkboards.
Our representations serve us. They extend our cognitive apparatus, enabling us to think in ways that we would not be able to without them. In 14th century Europe, multiplication was a skill possessed only by the mathematically elite. Then Arabic numerals replaced Roman numerals and multiplication became an idea accessible to anyone.
Representations channel our thoughts, but they are not our thoughts. Further, we can invent new representations in order to channel our thoughts in new directions.
The word “radical” is taken to mean dramatically new or different, but the word stems from Latin radix meaning root. In this sense, a radical solution is not just new, but returns to the root. A radical solution sets aside previous assumptions in order to address the fundamental activity.
“We don’t know who discovered water but we are pretty sure it wasn’t a fish!”
If it is difficult to realize that we are even making assumptions in the first place, how can we set them aside?
One way to suss out radical solutions is to find connections between the activity in question and seemingly unrelated activities. At CDG we have on a wall an evolving collage of notations and representations used in diverse disciplines. Many of the ideas of Shadershop stem from discussions this poster has stimulated.
Borrowing Cognitive “Moves” from Photoshop
In particular, Shadershop connects the activity of shader programming to the activity of transforming and compositing layers in a graphics editor like Photoshop.
The visibility toggle is analogous to “commenting out” a line of code. Moving and resizing an image is like applying a transformation matrix (a “multiply and add”) on either side (domain or range) of a function.
Photoshop’s fundamental innovation over bitmap editors (say Microsoft Paint) is treating the layer as the unit of manipulation rather than the pixel. Likewise, in Shadershop the unit of manipulation—tangible manipulation—is the function, rather than the string of characters.
Showing the Data
Traditional programming only shows the source code of the program and the final result of the computation. Once you decide that actually all of the data that the computation produces is potentially visualizable, the design challenge is to decide how and when to show it. When is it helpful and when does it distract? This can only be answered by understanding what the programmer is trying to do. So how can the programmer communicate this intent to the interface?
In Shadershop, the lines that are plotted on the main graph are determined by which functions are expanded in the outline.
Any function you see in the outline shows up on the main graph. An alternative design would be to have an additional toggle for each function, or perhaps a whole list of appearance settings for each function. I decided against this because showing and hiding needs to be fluid and because I wanted to strengthen the connection between the outline and the main graph.
Related, the pan and zoom of every thumbnail in the outline is the same as the pan and zoom of the main graph. You need this to make comparisons. Keep everything the same, except the differences that matter.
Live Coding vs. Direct Manipulation
A typical programming interface will show a program’s code but not its behavior. A program’s behavior becomes visible when we show the data the program uses and produces—inputs, intermediate values, and outputs.
Live coding means changing the program by manipulating the code view and seeing how your changes affect the data with continuous feedback.
[GFY scrubbing inspector values]
Direct manipulation programming means changing the program by manipulating the data view. It is “direct” manipulation because you change the program within the same cognitive frame that you use to understand its behavior.
[GFY moving handles]
With live coding, the human programmer needs to translate every creative impulse into code. Direct manipulation aims to minimize this cognitive burden by having the programmer express her intention in the frame that she understands the behavior and having the computer perform the translation.
I currently think that the ideal programming interfaces of the future will have both manipulable code and direct manipulation of behavior, but one way to force the issue of direct manipulation programming is to simply not have a manipulable code view. This is the design strategy that’s used in Recursive Drawing and taken further in Matthias Graf’s Vogo.
Future Directions
Shadershop is intended as a proof of concept that direct manipulation interfaces for shader-like programming are viable and worth pursuing. There are plenty of ways Shadershop could be improved.
This section addresses two trickier design problems that will probably not succomb to incremental improvements but will require another running start at the problem—that is, another iteration in the evolution above.
Showing Composition
I’m quoting an email from Bret Victor here because it addresses a challenging issue in Shadershop and because it’s a great example of exploring an idea visually—in this showing an extension to the interface through mockups. This is (obviously) a great way to critique interfaces. Put pictures in your emails!
I was thinking about how to make composition clear. Adding A + B = C is pretty easy to make sense of, because A, B, and C share the same domain. But when composing A . B = C, A’s range maps to B’s domain, and it can be confusing what’s going on. A couple simple techniques might be:
Indicate which parts of B are being sampled by A. In the picture below, the portion of the sine that is actually used is drawn heavier, and the unused portion is lighter and dashed:
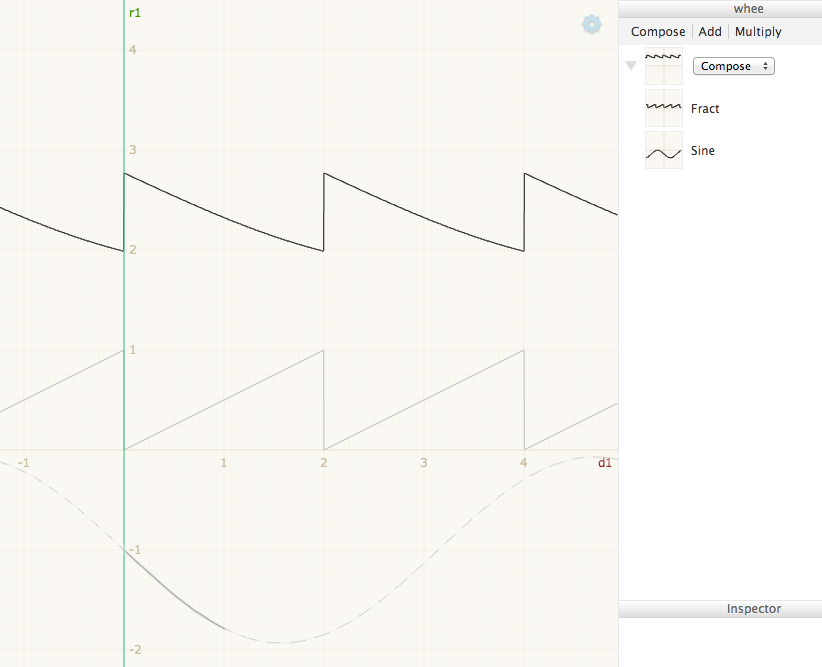
Interactive inspection. Mouse over a point on the output function, and see the points of the input functions that contributed to that output point:
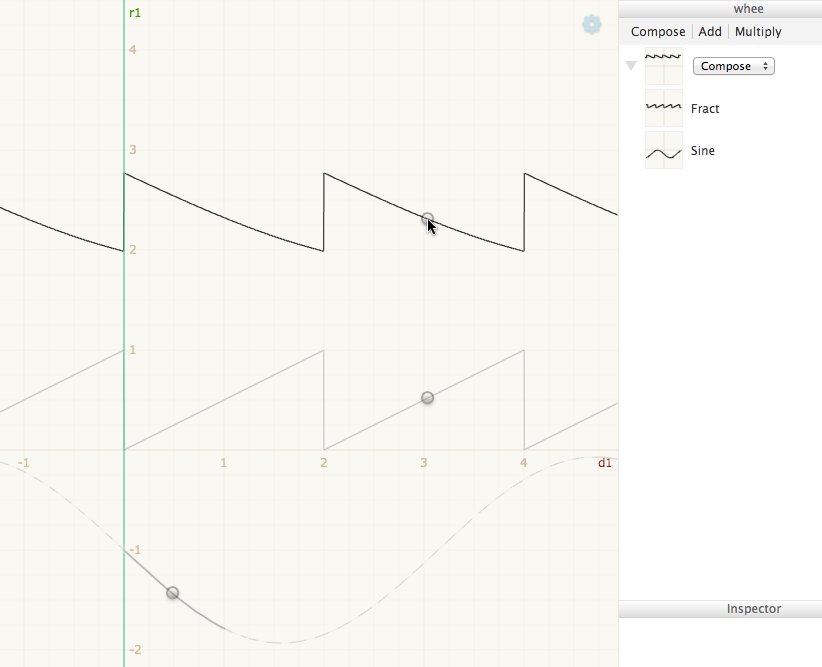
You could also go the other way — mouse over a point on an input function, and see all the output points where that point was “used”:
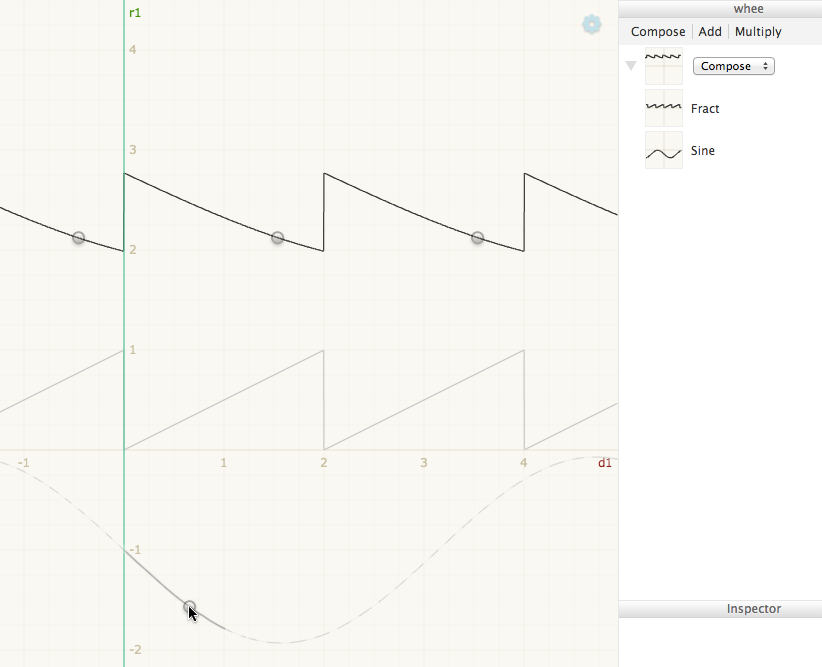
You could probably combine them in some way similar to Nile Viewer, so mousing over any point highlights both where that point came from and where that point went. (It was easier with Nile Viewer because data flow was represented spatially — inputs were up and outputs were down — whereas your dependencies are more spread around the canvas, so you would need some sort of graphical convention to indicate the direction of data flow.)
The hope is that, by skimming over the functions, you can build up an understanding of where that function came from and where it went.
Additional Visual Representations
Shadershop uses two visual representations: Cartesian graphs to visualize functions from 1D to 1D and color maps to visualize functions from 2D to 1D.
Internally, all the numbers in Shadershop are implemented as four dimensional vectors (and matrices). This is the just the standard vector size on GPUs, and seemed like a good target to reach for in the visualizations.
Unfortunately I only made it up to two dimensions, and even there the visual representation (color map) is missing a dimension in the range—it shows a function from 2D to 1D, not 2D to 2D. I gloss over this omission in the videos—watch carefully when I pre-compose floor on random in two dimensions.
Further, the color map only shows a single function at a time. The Cartesian slices are necessary in order to make comparisons, to see how multiple functions relate to each other.
It is an important open question whether this approach scales (cognitively) to higher dimensions, or how it can be made to scale to higher dimensions through techniques such as slices, projections, or small multiples.
Alternative Visualizations
Shadershop uses a color map to visualize a function from 2D to 1D. Here are several alternatives from a book on cartography.
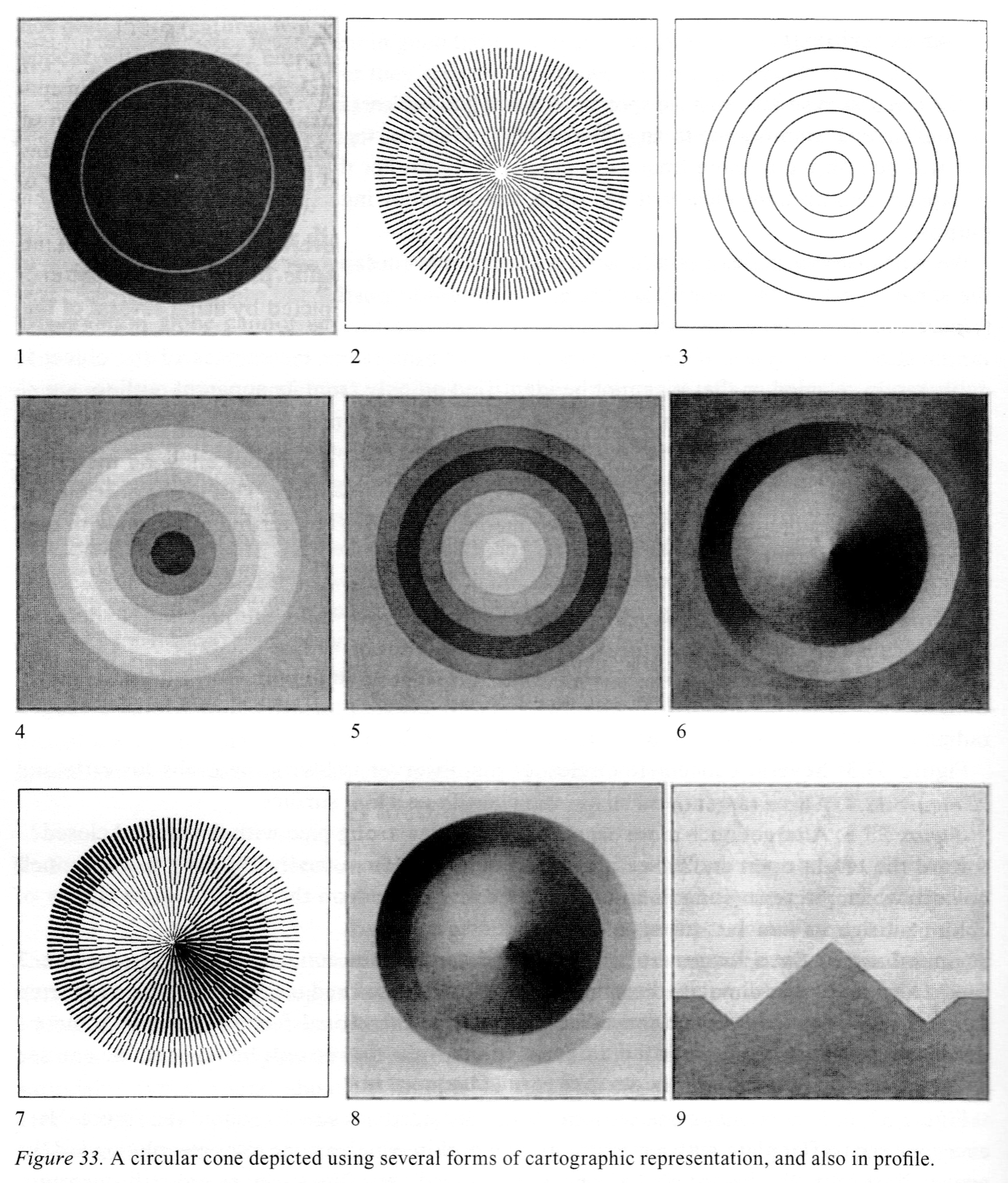
Here are some techniques to visualize the local effects of a function from 2D to 2D.
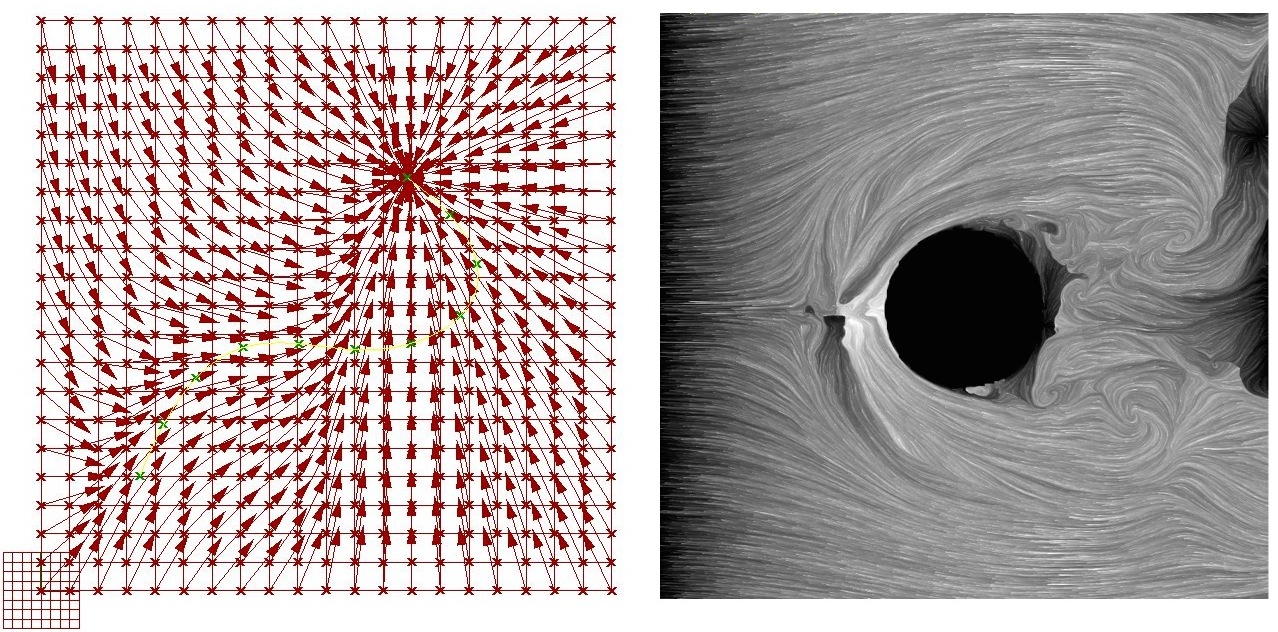
And here is an animated technique, by Fernanda Viégas and Martin Wattenberg.
To see the global effects of a function from 2D to 2D, you can visualize it with a spatial deformation on a known pre-image, as in Refractor.
To visualize a function from 3D to 1D, Ken Perlin applies a color map to the surface of a sphere with an interactive control to clip through it. Notice how this is just a way to “pan” the space. The sphere is used as a “camera” to look at the three dimensional texture.
Hopefully from the breadth of these examples you can see that we’re only scratching the surface.
All of these alternatives and more should be available in an environment for working with mathematical functions.
Bootstrapping
Intriguingly, each of the above visualizations can itself be programmed as a shader or using shader-like techniques. For example, you can write a pixel shader which draws a picture of a sphere textured with a given function if it’s allowed to sample from that function.
Thus a future version might let you create new, custom function visualizations within the interface. This idea of bootstrapping a direct manipulation interface within itself—the way that you can write a LISP interpreter within the LISP language—is a strong research direction.
Implementation Notes
Here I document my own approach to implementing direct manipulation interfaces.
Design of the Semantics
The semantics are the mathematics you are creating—the types of things in the system and what you can do with them. Often the hardest challenge is just choosing good words for the different types of things. Sometimes a diagrammatic notation is a helpful supplement.
For Shadershop, we have the notion of a Function which can either be a Built in Function (Line, Sine, Abs, etc.) or a Compound Function. A Compound Function consists of a combiner (Add, Multiply, or Compose) and a list of Child Functions. A Child Function consists of a function and a Transformation. A Defined Function is a Compound Function whose combiner just takes the last child. Additionally a Defined Function has a label and is allowed to be used within multiple Compound Functions—it can have multiple parents, so to speak.
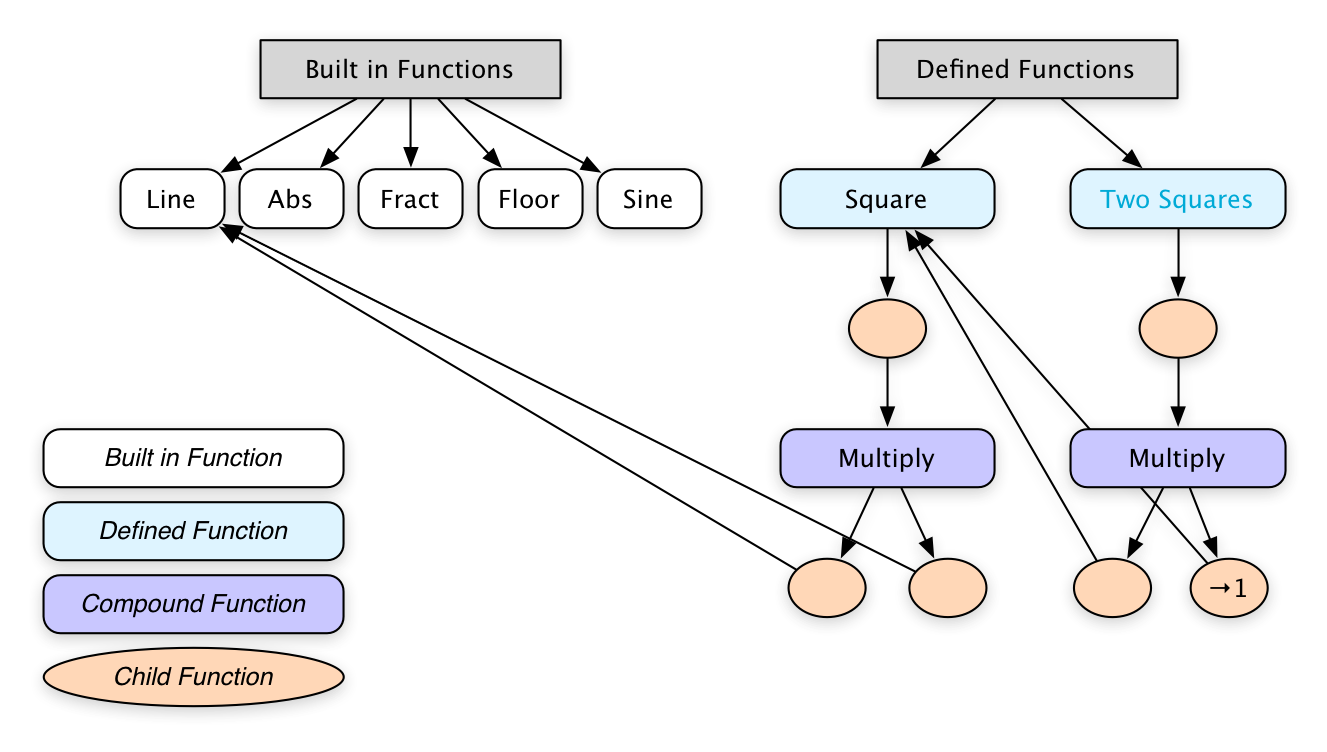
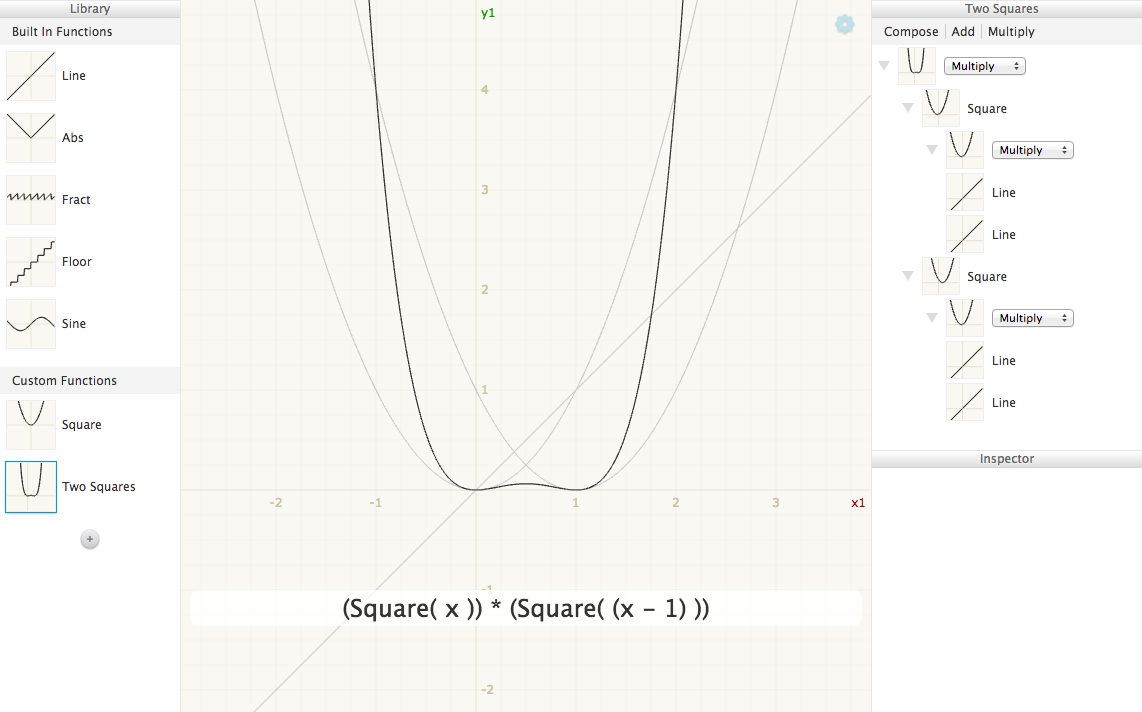
Sometimes the semantics are given. For example Recursive Drawing borrowed semantics without much modification from Context Free. The earlier Shadershop prototypes were concatenative variants on GLSL. But things get more exciting, and much trickier, when the semantics coevolve with the affordances of the new interface.
Implementation of the Semantics
I generally represent a program as a data structure, in particular as a graph. I think the term of the art is Abstract Semantic Graph.
When I’ve talked to programmers who want to make new interfaces for programming, an impulse that often arises is to make a new text-based language first, and then make a new interface that manipulates the text-based representation under the hood. Unless your intent is to make a text-based programming language, I think this is a mistake. It distracts from the opportunities of direct manipulation interfaces, and corrupts your initial impulses with the affordances that the text medium naturally encourages. You end up fiddling with parsers just to experiment with your semantics. Better, in my opinion, is to start with a data structure representation of your “source code” and get right to work on the interpreter and interface!
Text-based languages get parsed into trees. Because trees can’t have cycles, you generally need to refer to other nodes elsewhere in the tree indirectly, with some sort of name or identifier. I prefer to leapfrog this issue and just store my program as a graph rather than a tree. This representation makes it clear that a name is just a label, and you can change a name in one place and it changes everywhere, rather than making a dead link.
A very practical tip: make a way to serialize and deserialize the program representation. That is, implement auto-save! Don’t kill your program state every time you refresh your interface. The reason for this is that you want to live in your interface, not your code editor. Therefore make it painless to leave your code editor and come back home to your interface.
In Shadershop, I wrote a naive object graph serializer that creates a JSON representation of my program state. Any time I successfully render the interface I save the program representation to localStorage. So when I’m working on a new feature or fixing a bug, I can refresh the browser but not have to rebuild the thing I’m using to test the feature. I don’t save when the interface fails to render, and this usually prevents the saved program representation from getting into an inconsistent state.
Implementation of the Interface
All the DOM is rendered with React. I don’t use React’s “state” at all, just “props”. Nor do I track what state is “dirty” and needs rerendering. I just rerender everything after every mouse and keyboard event. I like this because I can think of rendering as a pure function from my program representation to HTML and I don’t need to do any bookkeeping about what needs updating when. I try to banish all “computer-y” considerations (e.g. bookkeeping) from my thought space so that I can focus all of my attention on exploring interface possibilities.
Interactive components are generally easy to express in React if they are self-contained. For example, to implement sliders, control points, or text fields, the pattern consists of passing in a value property as well as an onChange(newValue) callback which is responsible for doing whatever is necessary to make value equal to newValue. This onChange responsibility may be more or less involved, but the component is encapsulated from this logic.
However, it is tedious and sometimes a challenge to implement interactions which are not self-contained. For example, dragging something from one place to another requires global coordination. In particular, I felt that implementing the live reorderable outline view was harder than it needed to be. If you are a framework designer, this is a problem that needs to be solved!
The cartesian graphs and color maps are rendered with WebGL. I have a compiler that takes any Function from my program representation and turns it into a string of GLSL code. I try not to think about performance but I had to do some optimizations here in order to make dragging feel smooth.
You can only have so many WebGL canvases on the page before the browser complains, so I cheat with one canvas overlayed full screen and then have a render step where I find rectangles that need to have something drawn and draw appropriately.
Graphic Design
I’m not a great graphic designer but I think I get it good enough so that it doesn’t distract.
The graphic design needs to help the eye organize the information without drawing attention away from the content. This implies using subtle colors—only high enough contrast for the task, but no higher—see for example the grid lines on the graph.
The same goes for borders, shadows, and gradients. They’re just there to help the eye parse the interface, in this case to distinguish between the “content” data and interface “chrome”, but they should not draw attention to themselves. Indeed, borders should be eliminated wherever possible. They are a lazy way to organize information.
Edward Tufte’s books are well worth reading to see examples of great visual design and analysis of why it works.
Also, take an architecture studio class if you have the opportunity—you’ll learn the subtle tricks that make a drawing “pop”.
I use a CSS preprocessor to let me use variables in my CSS. This is important to keep the spacing sizes, colors, etc. consistent. The eye is drawn to elements that break the pattern, so having inconsistent spacing will distract the eye unnecessarily.
It has helped me immensely to have my CSS auto-update without having to refresh the page so that I can tweak the styles with a much tighter feedback loop.
Bootstrapping
The point of creating these interfaces is to tighten the feedback loop between the creator’s mental model and the computational artifact. Tighter both in terms of response time (continuous feedback versus turn-based feedback) and cognitive distance (spatial manipulation for spatial domains). Give the creator a direct connection to the work.
The computer’s job is to support the creative process. It should handle all the tedium so that the human creator can focus entirely on exploring creative possibilities. It should automatically “translate” all data into representations cognitively suitable for the task.
Similarly, it’s important for us to embody these values during the design and development of these interfaces. By saving the program representation instead of destroying the world when we “recompile”, we eliminate tedium from our own workflow and encourage creative exploration. By forgoing a text representation, we can more quickly escape our code editor and begin exploring new representations and new interaction possibilities.
The human and the computer each bring their own unique strengths to the collaboration. We must allow the computer to take responsibility for the tasks it is uniquely suited to, while allowing ourselves to take responsibility for the tasks we are uniquely suited to.

